
Znaki wodne w tekstach AI. Jak algorytmy je ukrywają?
Inspiracją do napisania tego artykułu jest nagranie, które pojawiło się kilka tygodni temu na zagranicznym TikTok.u. W filmiku pokazano, że w kodzie HTML tekstu skopiowanego z CzatGPT pojawiły się ślady i … Od razu zaczęła się snuć teoria spiskowa. Pojawiają się nagarnia w których stawiane są śmiałe tezy, że znaki w CzatGPT są wstawiane, ponieważ firma chce nas śledzić. Dodatkowo sporo osób powtarza, że znaki te działają na szkodę odbiorców, ponieważ wpływają na SEO i pozycjonowanie. No i plagą niestety jest już to, że w przestrzeni online możemy natknąć się na artykuły na blogach, które powielają nieprawdziwe informacje. Dlatego zdecydowałam się napisać ten artykuł. Zależy mi na tym, aby odkryć podstawy, dzięki którym będziemy mogli bezpiecznie korzystać z programów AI.
Okazuje się, że wiele osób z którymi rozmawiam, woli nawet nie zauważać tego, że dobrze napisany tekst, może nosić znamiona programu AI. Sama kilka dobrych lat temu byłam zaskoczona, kiedy po raz pierwszy usłyszałam o tak zwanym znaku wodnym, który jest wszywany w treść na stronie internetowej. Domyślam się też, że zaraz po przeczytaniu tego artykułu pojawią się głosy tych, którzy będą chcieli dodać coś od siebie w swoich artykułach czasem po to, aby rozwinąć temat, a czasem po prostu po to, aby pokazać, że posiadają wiedzę. I żeby było wszystko jasne, to naprawdę dobrze, bylebyśmy nie tracili z oczu sedna i oznaczali źródła skąd pochodzi wiedza którą się dzielimy, ponieważ nigdy nie wiemy, czy tekst który czytamy nie posiada znaków wodnych.
Załóżmy, że mamy sytuację, w której zlecamy napisanie artykułu. Osoba, która tworzy dla nas tekst korzysta z programu AI, o czym nas wcześniej nie poinformowała. Publikujemy treść na swojej stronie i idziemy dalej. Nie zastanawiamy się co może być z tekstem nie tak. Zwłaszcza wtedy, kiedy używane są w tekście „mądre” słowa i całość wygląda profesjonalnie. Tymczasem w tle wygenerowanego tekstu przez program AI, może ukrywać się coś, czego nie widać gołym okiem. Coś co może uderzyć w naszą markę i jej wiarygodność, narażając nas na konsekwencje prawne. To tzw. cyfrowe wodne znaki, które zostawiane są w generowanych treściach AI w niewidoczny dla nas sposób.
Tak, dobrze wiem, jak to brzmi. Trochę jak kolejna teoria spiskowa. Ale niestety, to prawdziwe ryzyko dla reputacji marki, bezpieczeństwa prawnego, a nawet widoczności w Google. Zignorowanie tych znaczników w tekście może nas naprawdę drogo kosztować.
Pracując z klientami dostrzegam, że łatwo wpadamy w pułapkę AI. Sztuczna inteligencja tworzy logiczne i czytelne treści, dając nam złudne poczucie bezpieczeństwa. Dlatego jesteśmy przekonani, że nikt nie zauważy tego, że tekst pochodzi z programu sztucznej inteligencji.
Dzisiejsze algorytmy potrafią wychwycić cechy, które wskazują na to, że tekst został wygenerowany przez platformę AI. Czasem nawet wtedy, kiedy tekst został napisany przez człowieka. Niestety nie wszystkie programy rozpoznają to skutecznie. Część śladów wciąż pozostaje niewidoczna zwłaszcza dla narzędzi, które posiadają nieaktualizowane algorytmy. Na podobnych zasadach działały kiedyś tradycyjne programy do wykrywania plagiatów.
Pracuję z tekstami i algorytmami od lat. Tematem zaczęłam się interesować zanim jeszcze programy AI zyskały popularność. Widzę, jak te narzędzia się zmieniają i jak zmienia się sposób, w jaki zostawiają swoje ślady. Właśnie dlatego jestem ostrożna i doradzam to samo innym. Znaki w tekstach stosowano nawet wtedy, kiedy tak zaawansowanych narzędzi AI nie było jeszcze na rynku. Prawdę mówiąc temat znaków wodnych w tekstach sztucznej inteligencji to tak naprawdę tylko ułamek tego, czego powinniśmy unikać w generowanych treściach.
Co więcej. Takie ślady wodne wykorzystywane są nie tylko przez programy AI. Zmienia się jedynie ich forma, subtelność oraz sposób ich ukrywania. Pisałam o tym w jednym z poprzednich artykułów – Jak google rozpoznaje treści CzatGPT . Opisałam w nim, jak wcześniejsze wersje narzędzi AI stosowały specjalne ślady w generowanych tekstach. Dlatego uważam, że warto sobie uświadomić, że to, co dzisiaj wygląda na nowy problem, tak naprawdę towarzyszy nam już od dawna.
Jeżeli tworzymy treści, działamy w marketingu, albo korzystamy z narzędzi tzw sztucznej inteligencji, to warto posiadać aktualną wiedzę, która mówi nam o tym, gdzie czekają na nas ukryte pułapki. Jakiś czas temu jeden z moich klientów opowiadał, jak kiedyś skopiował tekst z generatora treści i docelowo kosztowało to firmę więcej, niż mógł przewidzieć. Dlatego piszę ten artykuł po to, aby pomóc swoim czytelnikom w unikaniu takich sytuacji. Uważam, że warto wiedzieć jak tworzyć treści wolne od AI, które będą przyjazne dla algorytmów oraz czytelników.
Spis treści:
- Czym są znaki wodne w tekstach AI?
- Jak naprawdę działają ślady wodne zostawiane przez programy AI?
- Jak algorytmy ukrywają znaki wodne generowane w tekstach AI?
- Jak unikać znaków wodnych zostawianych przez AI?
- Jak wykrywać znaki wodne w tekstach AI?
- Jak wyglądają ślady AI w tekście?
- Naukowa wersja znaków wodnych w tekstach sztucznej inteligencji.
- Błędy modeli AI i ich konsekwencje.
- Q&A
Czym są znaki wodne w tekstach AI?
Znaki wodne, które zostawiane są w tekstach AI, są to niewidoczne dla ludzkiego oka cyfrowe odciski algorytmów. Mogą umożliwić wykrycie skąd pochodzi napisany tekst. Programy sztucznej inteligencji mogą celowo zostawiać specjalne ślady w swoich tekstach. Dodatkowe znaki mogą być zapisane w formie konkretnych, zakodowanych sygnałów w postaci. Takich jak np. wzorów długości słów, interpunkcji, tokenów, albo kolejności synonimów. Głównym celem tych znaków jest pomoc w unikaniu plagiatów, wykrywaniu nadużycia oraz ochrona praw autorskich. Jednak wykorzystuje się je także do np. walki z dezinformacją, czy phishingiem.
Niektóre programy AI generują treści według matematycznego wzoru, który naśladuje naturalny język, ale nie jest w pełni losowy. W odpowiedzi na polecenie użytkownika, program AI dobiera słowa zgodnie z rozkładem prawdopodobieństwa, a to tworzy charakterystyczny wzorzec ten tzw. znak wodny AI. Chociaż dla ludzkiego oka tekst wygląda zupełnie naturalnie, jego struktura może zawierać pseudolosowy rytm, który przypomina ten stosowany w automatach hazardowych. Właśnie ten schemat może zostać odczytany przez algorytmy Google jako „sygnatura AI”.
Ślady w tekstach dzielimy na dwie główne kategorie:
- Techniczne, które wprowadzane są na poziomie kodu HTML (np. ukryte znaki, elementy).
- Stylistyczne, które wynikają z charakterystycznych dla modelu językowego wzorców budowania wypowiedzi.
Obie formy pozostają niewidoczne dla przeciętnego użytkownika, jednak specjalistyczne narzędzia i analizy językowe często pozwalają je wykryć. Znaki wodne w tekstach AI mają kilka charakterystycznych cech, które pozwalają zidentyfikować ich pochodzenie i sposób działania:
- Twórcy programów AI projektują je celowo po to, aby umożliwić rozpoznanie źródła tekstu i zabezpieczenie jego autorstwa.
- Specjalne znaki umieszczane są zarówno w kodzie HTML, jak i w strukturze językowej. Wykorzystują m.in. długość zdań, kolejność słów czy specyficzne schematy stylistyczne.
- Ślady zostawione w treści mogą odczytać zazwyczaj tylko specjalistyczne narzędzia, albo algorytmy opracowane przez właściciela danego modelu.
- Cyfrowe ślady AI działają podobnie jak cyfrowy podpis, albo cyfrowe DNA.
Tekst z takim śladem wygląda zazwyczaj zupełnie naturalnie i nie traci na czytelności, ponieważ odciski cyfrowe w tekstach AI nie ingerują w samą treść, ani formatowanie. Eksperci i dedykowane systemy jednak mogą zidentyfikować pochodzenie tekstu, zwłaszcza wtedy, kiedy analizują ukryte wzorce, albo statystyczne cechy językowe.
Ukryte ślady w treści są kluczowe do kontrolowania rozpowszechniania treści. Nie wpływają one na warstwę wizualną, a jednocześnie umożliwiają zabezpieczanie content.u, wspierają działania prawne i pomagają platformom wykrywać masowe publikowanie nieoznaczonych tekstów AI.
Programy do generowania treści AI działają na takiej zasadzie, jak kiedyś działały miksery (tak mówiłam na programy z których korzystały agencje, albo osoby, które tworzyły treści). Tak w uproszczonej wersji … Osoba, zazwyczaj pracująca w agencji marketingowej, która miała stworzyć jakiś artykuł, wybierała kilka branżowych blogów z danym tematem i wrzucała teksty w generator tekstów. Taki program miksuje je i generuje „nowe”. Miksując automatycznie usuwają specjalne znaki z pobranych artykułów, nadpisują je dodając do wygenerowanego tekstu swoje ślady.
Z moich obserwacji wynika, że spora grupa użytkowników AI nie zdaje sobie sprawy, że kopiując tekst wygenerowany przez program, przenosi na swoją stronę wraz z tekstem niewidoczną sygnaturę ukrytą w tle treści. Dlatego uważam, że każdy użytkownik programów do generowania treści powinien znać działanie cyfrowych śladów. Temat ten jest ważny, ponieważ dzięki wiedzy dbamy o bezpieczeństwo swojej firmy, ale także o widoczność w przestrzeni online.
Warto także zauważyć, że każdy autor na swojej stronie pozostawia swój „cyfrowy odcisk palca” poprzez unikalny styl pisania, specyficzne sformułowania i rytm zdań. To również forma ukrytych znaczników, chociaż naturalna i niewymuszona. Ponadto, nawet ten artykuł zawiera ślady zapisane w treści, chociaż nie umieszczono ich w nim celowo.
Jak naprawdę działają ślady wodne zostawiane przez programy AI?
Ślady wodne w tekstach generowanych przez programy AI działają jak cyfrowy odcisk palca. Narzędzia AI osadzają specjalne ślady w kodzie HTML, albo w samej strukturze języka i pozostają one niewidoczne, dopóki odpowiedni algorytm ich nie odczyta. Takie specjalne znaki umożliwiają identyfikację źródła tekstu, a w niektórych przypadkach także konkretnego programu, użytkownika oraz sesji.
Na poziomie kodu HTML program może dodawać komentarze, atrybuty, albo znaczniki, które nie wpływają na wygląd tekstu, ale pozwalają śledzić, kto wygenerował tekst i gdzie go opublikowano. Najczęściej spotykane niewidoczne znaki to:
- ZWS (Zero-Width Space) – działa jak dodatkowa spacja, ale jest niewidzialna,
- ZWJ (Zero-Width Joiner) – łączy znaki bez wizualnej zmiany wyglądu,
- ZWNJ (Zero-Width Non-Joiner) – separuje znaki, które normalnie są połączone.
Takie identyfikatory mogą być wykorzystywane do tego, aby przypisać tekst do konkretnego użytkownika, ale także do kontroli zgodności z regulaminem platformy, śledzenia sesji, identyfikacji źródeł przecieków, plagiatów, albo odtworzenia kontekstu rozmowy.
Program AI zostawia ślad cyfrowy także na poziomie językowym w formie ukrytych wzorców w samym stylu. Na tym poziomie algorytm manipuluje długością zdań, powtarzalnością wyrażeń, specyficzną składnią oraz rytmiką wypowiedzi. Czasem także celowo wprowadza specjalne błędy językowe, albo korzysta z nietypowych konstrukcji gramatycznych. Te cechy są rozpoznawane nawet wtedy, kiedy przeredagujemy tekst.
Specjalne znaki działają także w SEO np. stosuje się je do ukrywania słów kluczowych. Często służą jako sprytny sposób na obejście systemów antyplagiatowych. Jednak w tym przypadku generowane znaki mają także swoje skutki uboczne, ponieważ mogą powodować błędy, zakłócać wyniki analizy treści oraz prowadzić do nieczytelnych kopii.
Jak algorytmy ukrywają znaki wodne w tekstach AI?
Algorytmy, które generują teksty z użyciem AI mogą ukrywać znaki wodne za pomocą mechanizmu tzw. pseudolosowości. Czyli pozornej losowości, która w rzeczywistości opiera się na matematycznie zdefiniowanych wzorcach. Tekst wydaje się naturalny i nieprzewidywalny, program działa na podstawie rozkładów prawdopodobieństwa np. że po słowie „sztuczna” najczęściej występuje „inteligencja”. Właśnie w tych mikrodecyzjach model może ukrywać znaki.
Zamiast jawnych symboli, znaki wodne są „wszywane” poprzez specyficzny wybór słów, szyków zdania, rytmu wypowiedzi, który jest z góry ustalony przez odpowiedni klucz. To forma niewidzialnego podpisu, który nie wpływa na sens tekstu, ale daje się matematycznie rozpoznać przy użyciu tego samego algorytmu, który go wygenerował.
Przykład 1 Manipulacja synonimami
Program AI może pseudolosowo wybierać między wyrazami „ważny” i „istotny” według zakodowanego schematu binarnego (np. „ważny” = 0, „istotny” = 1). Sekwencja użyć tych słów tworzy binarny „ciąg wodny” możliwy do zdekodowania przez odpowiedni analizator.
Przykład 2 Długość zdań jako klucz
W niektórych przypadkach długość kolejnych zdań może być zakodowanym wzorcem np. zdania parzyste oznaczają 1, nieparzyste – 0. Tak zbudowany wzorzec tworzy cyfrową sygnaturę osadzoną w rytmie wypowiedzi.
Przykład 3 Kolejność słów w kolokacjach
Model AI może zdecydować się na mniej popularne, ale wciąż poprawne gramatycznie szyki np. „system AI” zamiast „AI system” zgodnie z pseudolosowym schematem, który tylko pozornie wynika z naturalnego wyboru.
Znaki wodne i pseudolosowość mają mocne podstawy matematyczne. Pseudolosowość opiera się na funkcjach deterministycznych, które generują ciągi pozornie przypadkowe. Możliwe są do przewidzenia, zwłaszcza wtedy, kiedy znamy algorytm i tzw. seed (ziarno losowości). Z kolei znakowanie wodne bazuje często na kodowaniu binarnym, kodach korekcyjnych i modelach entropii, a to wszystko są pojęcia z zakresu informatyki teoretycznej i statystyki.
W uproszczeniu … to nie magia, to ukrywanie informacji w strukturze języka za pomocą przewidywalnych, ale trudnych do zauważenia matematycznych reguł.
Jedną z metod ukrywania znaczników w tekstach algorytmów jest modyfikowanie prawdopodobieństw tokenów. Model wybiera określone słowa, albo frazy z większym lub mniejszym prawdopodobieństwem, tworząc w ten sposób charakterystyczne wzorce językowe (np. długość zdań, rytm, powtarzalność). Takie wzorce dla zwykłych użytkowników są trudne do zauważenia, ale możliwe do wykrycia podczas analizy statystycznej.
Kolejną techniką jest wstawianie do tekstu ukrytych, niewidocznych znaków Unicode takich jak ZWJ czy ZWS. Znaki te wprowadzają w kod tekstu subtelne zmiany, które są możliwe do wykrycia przez systemy analityczne, które umożliwiają precyzyjne śledzenie pochodzenia i struktury treści.
Jest także metoda związana z wprowadzaniem subtelnych odchyleń statystycznych. W tej wersji algorytmy zachowując poprawność i płynność tekstu zmieniają strukturę językową, jednocześnie pozwalając specjalistycznym programom na wykrycie treści AI.
Techniki ukrywania wodnych śladów w tekstach pozwalają twórcom i platformom skutecznie odróżniać teksty napisane przez ludzi, od tych generowanych przez maszyny, a to moim zdaniem może zwiększyć poczucie bezpieczeństwa w kontekście ochrony przed dezinformacją i nadużyciami.
Warto pamietać także o tym, że każde ukrycie znaku odbywa się już na etapie generowania tekstu. Algorytm wybiera odpowiednie słowa, struktury i znaki w taki sposób, aby zakodować „podpis” sztucznej inteligencji, bez ingerowania w styl wypowiedzi. Użytkownik otrzymuje logiczną treść, ale specjalistyczne oprogramowanie może zidentyfikować jej cyfrowe pochodzenie.
Jednym z przykładów takiego rozwiązania jest SynthID, stworzony przez DeepMind. Narzędzie to dodaje do treści niewidoczne znaczniki, które są odporne na modyfikacje i umożliwiają w późniejszym terminie potwierdzenie, że daną treść wygenerował program AI.
Podobne możliwości oferuje także program OpenAI Watermark Detector, który analizuje teksty pod kątem charakterystycznych wzorców generowanych przez sztuczną inteligencję. Tego typu rozwiązania można już testować, na przykład za pomocą platformy Humbot AI Watermark Detector.
Twórca może chronić swoją treść przed bezmyślnym kopiowaniem stosując skuteczne działania takie jak stosowanie charakterystycznych fraz, albo oryginalnych konstrukcji. Takie znaki nie zaburzają płynności lektury, a mimo to pozostają trudne do wymyślenia przez osoby postronne.
Modelom AI zależy na tym, aby ślady były zostawiane, ponieważ zapewniają one transparentność w generowaniu treści, wykrywają nadużycia, kontrolują styl i jakość treści. Jednak podstawowym zadaniem jest dostosowanie się do regulacji prawnych i monitorowanie pochodzenia danych.
Uważam, że warto zwiększać świadomość na temat ukrytych śladów w tekstach AI, ponieważ zrozumienie tego jak działają algorytmy, pozwala nam unikać nielegalnego rozpowszechniania treści, chronić swój wizerunek w internecie i bardziej świadomie korzystać z narzędzi AI.
Jakie ryzyko niesie technika ukrywania znaków wodnych w tekstach AI?
Technika ukrywania znaków wodnych w tekstach generowanych przez AI opiera się na subtelnych, pseudolosowych modyfikacjach statystyki językowej. Dla człowieka tekst wygląda całkowicie naturalnie. Jednak i tak algorytmy potrafią odczytać ukryty wzór i zidentyfikować źródło np. konkretnego modelu językowego, albo sesji. I właśnie w tym miejscu zaczyna się problem.
Znaki wodne, mają wspierać bezpieczeństwo i walkę z dezinformacją, jednak niosą także realne ryzyko naruszenia prywatności. W przypadku, kiedy mechanizm ich odczytu znajdzie się w niepowołanych rękach np. konkurencji, instytucji rządowej, firmy, która analizuje treści, albo platformy social media, może on posłużyć do śledzenia kto, kiedy i gdzie korzystał z konkretnego modelu AI. W niektórych przypadkach możliwe jest nawet połączenie znaku wodnego z konkretnym kontem użytkownika.
Dodatkowo, użytkownicy często nie są świadomi, że tekst, który publikują, zawiera ukryte metadane. A skoro można go odczytać, to można też przypisać autorstwo, powiązać z konkretną sesją, albo wykorzystać jako dowód w sytuacjach spornych np. prawnych, albo zawodowych.
Przykład? W 2024 roku jedna z dużych firm edukacyjnych udowodniła studentowi plagiat. Przeanalizowała tekst wygenerowany przez ChatGPT i udowodniła, że zawierał on charakterystyczny układ pseudolosowych tokenów, który jest zgodny ze znakiem wodnym modelu GPT-3.5. Inna sprawa dotyczyła wewnętrznych materiałów szkoleniowych firmy IT. Po przecieku wykazano, że ich treść powstała z pomocą AI, mimo oficjalnego zakazu.
Dlatego, mimo że technika znaków wodnych wspiera transparentność, może też zostać wykorzystana przeciwko użytkownikowi. Warto mieć świadomość, że korzystanie z AI nie jest już anonimowe. I chociaż nie każda treść zostaje oznaczona, rosnąca precyzja algorytmów i rozwój detektorów może sprawić, że za kilka miesięcy nawet „naturalnie” wyglądające teksty będziemy mogli zidentyfikować z dużą pewnością.
Jak unikać znaków wodnych zostawianych przez AI?
Jeżeli chcemy skutecznie unikać znaków wodnych, które są zostawiane w tekstach przez programy AI, to warto mieć świadomość tego, że całkowite ich usunięcie jest obecnie niemal niemożliwe. Na początek warto zadać sobie pytanie … Po co chce usunąć te znaki? Czego się obawiam? Dopiero wtedy można podejść do tematu unikania znaków z programu AI. Niewidoczne ślady dla zwykłych użytkowników są niewidoczne, a skuteczne narzędzia do ich wykrywania jeszcze nie istnieją. Mimo to możemy zastosować praktyczne kroki, które pozwolą nam zminimalizować ryzyko obecności śladów zostawianych przez generatory treści.
- Redaguj, zanim opublikujesz – zawsze przejmujmy kontrolę nad tekstem. AI to narzędzie, a nie gotowy produkt. Najlepszą forma jest zainspirowanie się wygenerowanym tekstem. Przepisujmy zdania, zmieniajmy szyk, stosujmy własny styl pisania. Przekształcenie treści eliminuje potencjalne znaki wodne w tekstach AI, ale także zwiększa jej unikalność i wiarygodność. Zmieniaj długości zdań. Parafrazuj. Przetłumacz na inny język i z powrotem. Warto także wiedzieć o tym, że … Google lepiej ocenia treści autentyczne i oryginalne.
- Pamiętaj o prawach autorskich – zastanów się dlaczego ukryte znaki Ci przeszkadzają? Dlaczego nie chcesz postawić na transparentność? Programy AI generują treści, miksują wiedzę, różne artykuły, które zostały już opublikowane na jakiejś stronie. Jeżeli podczas generowania treści w programie AI pojawią się odniesienia do artykułów, to warto je uwzględnić w swoim źródle.
- Używaj modeli, które nie stosują śladów cyfrowych – nie wszystkie systemy generowania treści AI wprowadzają ukryte znaczniki w kodzie HTML. Wybierajmy narzędzia, które jawnie deklarują brak technik znakowania, albo oferują kontrolę nad tym procesem. Korzystajmy z płatnych, certyfikowanych modeli o transparentnych warunkach zamieszczanych w licencjach. To może zminimalizować ryzyko problemów prawnych i jakościowych. Jednak i tak docelowo to my będziemy ponosić odpowiedzialność za opublikowaną treść.
- Mieszaj źródła i styl – teksty generowane z różnych modeli rzadziej zdradzają cyfrowy odcisk palca. Łączmy fragmenty pisane przez różne programy AI z własnym komentarzem. Przeplatajmy je cytatami, przykładami z praktyki, albo unikalnymi wnioskami. To sposób, który pozwala na unikanie sygnatur tekstowych, a także na zbudowanie pozycji eksperta w oczach czytelnika i algorytmu.
- Edukuj się regularnie – techniki wykrywania śladów w tekstach AI szybko się zmieniają. Śledźmy nowe badania, aktualizacje platform i rekomendacje specjalistów. Bierzmy udział w spotkaniach branżowych, takich jak SuperBizWizje, na których omawiamy najnowsze ryzyka i praktyczne przykłady z marketingu, AI, psychologii i prawa. Wiedza i świadomość to najlepsza ochrona.
- Unikaj zautomatyzowanego publikowania – masowe generowanie i publikowanie tekstów bez redagowania, to prosta droga do deindeksacji strony, utraty zaufania i potencjalnych roszczeń prawnych. Nawet jeżeli narzędzie deklaruje brak śladów AI. Zbyt „maszynowy” styl działa jak znak sam w sobie, który jest widoczny tylko dla algorytmów wyszukiwarek.
Ślady wodne w tekstach sztucznej inteligencji to realny problem w świecie cyfrowego content marketingu. Nie chodzi tylko o technologię, ale także o etykę, bezpieczeństwo i reputację marki. Zadbajmy o własną redakcję, świadomy wybór narzędzi i rozwój kompetencji, ponieważ to fundament tworzenia wartościowych i bezpiecznych treści.
Jeżeli chcemy usunąć ślady z tekstu wygenerowanego przez AI i zmienimy cały tekst, to i tak głębsze ślady cyfrowe pierwszego autora zazwyczaj zostaną. I tutaj wchodzimy na grunt łamania praw autorskich. Aktualnie w algorytmach programów AI jest sporo zmian, więc zapewne niebawem pojawią się także pierwsze zmiany w prawie.
Dlatego jeżeli chcemy unikać znaków w tekstach AI, to warto postawić na umiejętne posługiwanie się programami AI. Nie musimy stawiać na kopiowanie tekstów. Warto wykorzystać program do tego, aby nas wspomógł w tworzeniu treści. Tworzenie swoich tekstów pisanych z tzw palca jest najskuteczniejszą metodą unikania obcych znaków zostawianych w treści.
Pamiętaj o tym, że programy AI, zwłaszcza te zaawansowane, mają algorytmy dynamiczne, a to oznacza, że stosują różne metody znakowania np. do krótkich tekstów i do długich. Dodatkowo mogą stosować inne techniki znakowania. Takie ślady mogą być losowo modyfikowane, czyli rotacja odbywa się np. co tydzień, w którym zmienia się sposób kodowania bitów. Cyfrowe ślady to nie jedyny wzór, który jest zapisany na zawsze. One ewoluują wraz z modelem AI.
Model, który generuje treści się zmienia, dlatego detektor, który jest wytrenowany na starych danych będzie tracił skuteczność, a utrzymanie go w wersji aktualnej jest dość kosztowne.
Jak wykrywać znaki wodne w tekstach AI?
Wykrywanie znaków wodnych w tekstach AI wymaga od nas spojrzenia z dwóch perspektyw. Najpierw warto przeanalizować strukturę pliku lub kod HTML. Często to właśnie tutaj ukrywają się niewidoczne dla czytelnika znaki Unicode, które są obecne „pod spodem”. Równocześnie powinniśmy zwrócić uwagę na styl i rytm tekstu. Dlatego, że charakterystyczne frazy, powtarzające się wzory czy nietypowe układy zdań, mogą zdradzać sygnaturę algorytmu. Dopiero połączenie analizy technicznej z językową pozwali nam skuteczniej wykrywać ukryte znaczniki zostawiane w tekstach generowanych przez AI.
Metody wykrywania ukrytych znaczników:
- Analiza statystyczna tokenów (DetectGPT) – metoda została opracowana przez Stanford University, która polega na polega na analizie krzywizny funkcji log-prawdopodobieństwa generowanego tekstu przez model językowy. Teksty generowane przez AI często znajdują się w obszarach o ujemnej krzywiźnie tej funkcji.
Zastosowanie – pozwala na wykrycie tekstów AI bez potrzeby trenowania dodatkowych klasyfikatorów czy posiadania dostępu do modelu generującego. - Ukryte znaki Unicode – niektóre modele AI wstawiają niewidoczne znaki (np. ZWS, ZWJ), które nie wpływają na wygląd tekstu.
Zastosowanie – można zidentyfikować obecność takich znaków eksportując tekst do formatu HTML i analizując go w edytorze kodu. - Analiza stylometryczna (StyloAI) – metoda ta polega na analizie cech stylometrycznych tekstu, takich jak długość zdań, użycie słownictwa czy struktura gramatyczna. Analiza ta pozwala odróżnić tekst generowany przez AI od tych napisanych przez ludzi.
Zastosowanie – umożliwia identyfikację tekstów AI poprzez porównanie ich cech z bazą danych znanych wzorców pisania.
Co naprawdę możemy wykryć w tekstach AI?
- Układ językowy – narzędzia takie jak GPTZero, AI Writing Check, czy Writer AI Detector oceniają układ językowy tekstu, analizując długość zdań, powtarzalność struktur i styl. Programy te nie są w pełni wiarygodne, jednak czasami potrafią wskazać podejrzane fragmenty.
- Znaki specjalne – Zero-Width Space, Zero-Width Joiner, a także inne symbole Unicode, które mogą być zaszyte w tekście. Możemy je ujawnić eksportując tekst do pliku HTML i analizując go za pomocą edytora kodu.
- Wzorce statystyczne – zaawansowane modele detekcji, takie jak BypassGPT, wykorzystują analizę rozkładu tokenów. Dla specjalistów to często lepsza metoda niż zwykła edycja manualna, jednak nie zawsze skuteczna.
- Analiza porównawcza – zestawienie kilku wersji treści generowanych z różnych modeli, może pomóc nam ujawnić wspólne „ślady” algorytmu.
Ślady wodne mogą przyjmować różne formy. Oto przykład fragmentu kodu HTML z ukrytym znakiem ZWS:
Wstawiony znak ZWS zaznaczony na niebiesko jest widoczny w kodzie HTML tylko do momentu pierwszego kliknięcia. Później znika z podglądu, chociaż nadal jest obecny w treści. Podczas analizy treści odpowiednie algorytmy „zobaczą” go i odczytają ukryty znak. W jednym z nagrań na TikTok.u dokładnie pokazałam jak zachowuje się taki kod w tekście.
Jeżeli chcemy usunąć sygnatury tekstowe zostawiane w kodzie HTML to warto postępować zgodnie z tymi krokami:
Krok 1
Skopiuj podejrzany tekst i wklej go do programu – Usuń znak wodny. Możesz też użyć notatnika, jednak warto także dodatkowo sprawdzić czy znaki z kodu zostały usunięte.
Krok 2
W programie kliknij w przycisk – usuń i napraw
Krok 3
Dodatkowo użyj narzędzi detekcyjnych, takich jak DetectGPT, aby przeanalizować strukturę statystyczną tekstu.
Krok 4
Porównaj styl tekstu z innymi znanymi tekstami po to, aby zidentyfikować cechy charakterystyczne dla AI.
Warto pamietać, że urządzenia detekcyjne nie są nieomylne. Zdarza się, że błędnie oznaczają teksty, które zostały napisane przez człowieka jako generowane przez AI, albo odwrotnie. Dlatego zawsze warto łączyć analizę techniczną z doświadczeniem edytorskim. Trenerzy językowi i redaktorzy tekstów potrafią wykryć nienaturalną składnię, która wymyka się nawet algorytmom.
Regularnie testuję popularne narzędzia i sprawdzam ich skuteczność. Każdy z programów zapewnia nas, że w 99% wykrywa tekst AI. Wklejam tekst 1:1 wygenerowany np przez CzatGPT i sprawdzam, czy program rozpozna, że tekst pochodzi od AI. Nawet dzisiaj w trakcie pisania tego artykułu, wkleiłam tekst do kilku takich wykrywaczy, co też pokazałam w nagraniu na TikTok.u. Mimo tego, że umieściłam w treści charakterystyczne cyfrowe ślady, to tylko jeden program uznał, że tekst został wygenerowany przez sztuczną inteligencję i to jedynie w 60%.
Na podstawie przeprowadzonych wielu badań, które obejmowały analizę programów takich jak GPTZero czy BypassGPT, wykazałam (szczegóły znajdują się w dalszej części artykułu), że narzędzia te jednak nie osiągają oczekiwanej skuteczności na deklarowanym poziomie. Często sugerują, że tekst został wygenerowany przez program AI, a tak naprawdę został on napisany przez człowieka, albo na odwrót.
Rozpoznanie tekstów generowanych przez AI staje się coraz łatwiejsze także dzięki ludzkiej intuicji. Podczas jednej z SuperBizWizji, uczestniczka warsztatu pokazała dokument przekazany przez przełożonego. Już pobieżna analiza wykazała, że tekst zawierał typowe cechy treści AI. Czyli posiadał zbyt uporządkowaną strukturę, powtarzalną długość zdań i specyficzne słownictwo.
Zauważenie takich schematów ułatwia rozpoznanie pominiętych treści, a także dostrzeganie manipulacji narracją. Dla wielu użytkowników teksty AI są mylące, ponieważ ich „logika” brzmi przekonująco, nawet wtedy, kiedy zawierają nieprawdziwe informacje.
Podczas wykrywania śladów cyfrowych w tekstach napotykamy na pewne ograniczenia i wyzwania:
- Brak 100% skuteczności – żadna z obecnych metod nie gwarantuje pełnej skuteczności w wykrywaniu treści AI.
- Możliwość obejścia dodatkowych znaków – znakowanie treści może być omijane poprzez parafrazowanie, albo tłumaczenie tekstu.
- Ograniczenia analizy stylometrycznej – stylometryka może nie być wystarczająco skuteczna w identyfikacji treści AI. Zwłaszcza wtedy, kiedy modele generują teksty o wysokiej jakości.
Moim zdaniem obecnie najskuteczniejszą metodą wykrywania cyfrowych śladów wodnych jest połączenie analizy technicznej z oceną ludzką. Eksperci językowi i redaktorzy mogą zauważyć subtelne cechy tekstu, które umykają algorytmom. Jednak i tak możemy wykryć pewne statystyczne wzorce typowe dla danego programu AI. Znając temat możemy skupić się na schemacie uczenia maszynowego, analizie stylometrycznej, testów n-gramów. Niestety wykrycie konkretnego mechanizmu bez znajomości metody wstawiania jest bardzo trudne.
Ostatnio widziałam na jednym z nagrań TikTok.a, że osoba, która mówi sporo o sztucznej inteligencji pokazała stworzony program do wykrywania ukrytych śladów w tekstach. Zaczęłam się zastanawiać czy to możliwe, że z pomocą np. CzatGPT jesteśmy w stanie stworzyć taki program. I tu pojawiają się małe komplikacje. Możemy do tego tematu podejść detekcyjnie/statystycznie. Czyli program będzie analizował cechy stylometryczne i będzie porównywał z profilami znanych modeli.
Robot będzie trenowany na głębokim uczeniu, czyli sieci neuronowe oparte będą na dużych zbiorach danych, które będą rozpoznawać wzorce, których człowiek nie zauważył. Można też podejść do tematu rekonstrukcji podejrzanych algorytmów znakowania, wtedy próba odtworzenia działania znakowania odbywa się przez symulację i analizę kolokacji.
Jednak wyzwaniem będzie dla takiego programu na pewno tekst, który został przepisany, edytowany, albo przetłumaczony. Wtedy znaki zostają zniszczone. Utrudniona precyzja identyfikacji będzie także, w przypadku braku jawnych informacji o technice znakowania. Do tego niektóre AI nie używają żadnych odcisków cyfrowych.
Jak wyglądają ukryte ślady AI w tekście?
Znaki wodne w tekstach AI na pierwszy rzut oka dla użytkowników programu wyglądają … Jak zwykły kod HTML, albo tekst, który nie odróżnia się od całości. Programy AI mogą dodawać do swoich treści cyfrowe ślady w postaci ciągu specyficznych liczb, liter, albo specjalnych znaków. Algorytmy także mogą ingerować w tekst zostawiając specyficzne słowa, wyrazy, albo zmieniając budowę zdań. Często znaczniki są tak ukryte, że nie rzucają się w oczy. Tekst wygląda zupełnie normalnie, jest czytelny i logiczny. Jednak, kiedy zajrzymy pod powierzchnię np. otwierając go w edytorze kodu, możemy dostrzec drobne anomalie. Takie jak dodatkowe znaki, albo przerwy tam, gdzie ich nie powinno być. To właśnie cyfrowe odciski palców, które dla zwykłego czytelnika są niedostrzegalne, ale jednoznaczne dla narzędzi analitycznych.
W przestrzeni internetu można natknąć się na artykuły na różnych blogach, w których znajdują się dodatkowe znaki widoczne w kodzie HTML. Takim przykładem są:
- Klasa text -message, data -message -author-role =”assistant” oraz data -message-id – nie są to przypadkowe klasy. To specyficzne znaczniki używane w interfejsie programu AI. Nie są one potrzebne do samego wyświetlania tekstu. Służą do identyfikacji, kto napisał wiadomość (czyli AI vs. użytkownik), śledzenia sesji, albo ewentualnie odtworzenia kontekstu rozmowy.
- Obecność data -message- id z unikalnym identyfikatorem UUID (np. af482266 -f1c9-4140-975a- 803f924efccf) – to wewnętrzny identyfikator wiadomości. System generuje go dynamicznie. Nie potrzebujemy takich identyfikatorów w normalnym HTML-u blogowym czy edytorskim.
- Styl Tailwind (min -h- [20px], gap- 3, whitespace -pre- wrap) – to tzw klasy z frameworka Tailwind CSS, którego używa interfejs programu AI. One nie są generowane przez zwykłe procesory tekstu, edytory blogów czy Worda, to bardzo mocny znak źródła.
Niektórzy twierdzą, że generatory treści nie zostawiły w powyższych przykładach typowych znaków wodnych. Jednak zachowują funkcję identyfikacyjną. Mogą być wykrywane automatycznie przez narzędzia śledzące źródło tekstu oraz mogą sugerować, że ktoś skopiował całą strukturę HTML bez edycji. Właśnie to ułatwia platformie AI wykrycie momentu w którym użyto wygenerowaną treść. Czyli ślady te moim zdaniem spełniają rolę ukrytych znaczników.
Poniżej podaję przykład tekstu, który zawiera ukryte znaczniki włożone do treści. Użyłam do stworzenia tego tekstu programu AI. Wpisałam do niego odpowiednią komendę. Zostały użyte słowa, frazy, konstrukcje językowe które wplotłam w taki sposób, aby działały jak identyfikator autora. Takie „tekstowe znaki” często są trudne do zauważenia zwłaszcza dla zwykłych użytkowników, ponieważ nie wpływają znacząco na płynność czytania.
„Jak budować trwały wizerunek marki w świecie online?
W erze natychmiastowej komunikacji kluczowe staje się nie tylko to, co mówisz, ale jak długo odbiorca to zapamięta. Jedną z najczęściej pomijanych zasad jest powracająca przejrzystość , czyli zdolność marki do klarownego powtarzania swoich wartości, niezależnie od kanału komunikacji.
Kiedy projektujemy treści marketingowe, warto kierować się zasadą trójpoziomowego rozpoznania co:
Odbiorca widzi na pierwszy rzut oka,
Zapamięta po kilku godzinach,
Powie o marce za tydzień.
Właśnie ten efekt narracyjnego przesycenia sprawia, że odbiorca konsumuje nie tylko konsumuje treść, ale także zaczyna ją powtarzać, adaptować i oswajać – jak coś, co już zna.
Nie chodzi dziś o to, by mówić głośno – chodzi o to, by mówić zmyślnie bez echa.”
Czy widzisz w tekście jakieś znaki? Zapewne nie. A jednak są. Dzięki nim, nawet jeżeli ktoś skopiujesz ten tekst i zmienisz kilka słów, to ja jako autor spokojnie mogę łatwiej zidentyfikować kopię i udowodnić swoje autorstwo. To metoda stosowana jest m.in. przez niektóre profesjonalne agencje copywriterskie, czy twórców treści AI.
Wodne znaki, które ukryłam w tym tekście to:
– Jedną z najczęściej pomijanych zasad jest powracająca przejrzystość – (znak wodny to unikalna fraza, niespotykana w języku potocznym) – czyli zdolność marki do klarownego powtarzania swoich wartości, niezależnie od kanału komunikacji.
– Kiedy projektujemy treści marketingowe, warto kierować się zasadą trójpoziomowego rozpoznania (znak wodny to zmyślona, ale logiczna koncepcja):
– Właśnie ten efekt narracyjnego przesycenia (znak wodny to termin stworzony na potrzeby konkretnego autora) sprawia, że odbiorca nie tylko konsumuje treść, ale zaczyna ją powtarzać, adaptować i oswajać – jak coś, co już zna.
– Nie chodzi dziś o to, by mówić głośno – chodzi o to, by mówić zmyślnie bez echa (znak wodny to poetycka, ale trudna do spontanicznego wymyślenia fraza).
Tekst ten wrzuciłam do programu GPTZero, który gwarantuje, że jest w stanie na 99% wykryć tekst napisany przez AI. Otrzymałam informację, że treść została stworzona przez człowieka, co jest nieprawdą, ponieważ treść według mojej komendy stworzył program AI.
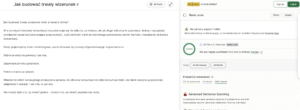
No to poszłam dalej. Tekst wkleiłam do BypassGPT i otrzymałam także informacje o tym, że tekst został napisany przez człowieka.

Rozpoznanie takich znaków wymaga aktualnej wiedzy związanej ze znakami wodnymi oraz uważnej analizy. Często tylko autor jest w stanie udowodnić, że dana konstrukcja jest jego własnością. To właśnie on dokładnie wie jak wygląda jego znak wodny, który zostawił w treści. Zwłaszcza wtedy, kiedy występuje w innych publikacjach, albo koresponduje z jego stylem.
Wykorzystanie śladów wodnych zostawianych w tekstach AI to skuteczna strategia ochrony twórczości. Wzmacnia ona pozycję autora i zniechęca do kradzieży treści. Budowanie eksperckiego wizerunku zaczyna się od autentyczności, a nie od kopiowania czyjejś pracy.
Naukowa wersja znaków wodnych w tekstach sztucznej inteligencji.
Temat znaków wodnych w treściach generowanych przez AI stał się także przedmiotem licznych badań. Naukowcy z OpenAI i University of Maryland zaproponowali tzw. „statystyczne znakowanie”. Metoda ta polega na modyfikowaniu struktury językowej. W tekście powstaje wzorzec trudny do usunięcia, który pozwala rozpoznać konkretne źródło. Zespoły badawcze eksperymentują także z ukrywaniem znaków Unicode, takich jak ZWS (zero-width space).
Autorzy badania A Watermark for Large Language Models wykazali, że można skutecznie wykrywać wodne znaki w tekstach AI, nawet po ich lekkiej edycji. Chociaż nie są one całkowicie odporne na parafrazowanie, czy „czyszczenie” przez inne modele.
Artykuł naukowców z Cornell University przedstawia także ciekawy temat dotyczący wodnych śladów zostawianych w tekstach przez AI. Możemy w nim przeczytać, że cyt.” Modele wielkojeślowe (LLM) wykazały niezwykłe możliwości generowania tekstów przypominających ludzki język. Przestępcy mogą nadużywać tych znaków, tworząc oszukańcze treści, takie jak fałszywe wiadomości i e-maile phishingowe, co budzi obawy etyczne. Znakowanie wodne jest kluczową techniką rozwiązywania tych problemów, która osadza wiadomość (np. Bit string) w tekście wygenerowanym przez LLM. Dzięki osadzeniu identyfikatora użytkownika (reprezentowanego jako bitowy ciąg) do wygenerowanych tekstów, możemy śledzić generowane teksty do użytkownika, zwane śledzeniem źródeł treści. Głównym ograniczeniem istniejących technik sygnalizacji wodnej jest to, że osiągają one nieoptymalną wydajność dla śledzenia źródeł treści w rzeczywistych scenariuszach. Powodem jest to, że nie mogą dokładnie lub skutecznie wyodrębnić długiej wiadomości z wygenerowanego tekstu. Naszym celem jest zajęcie się ograniczeniami.
W tej pracy wprowadzamy nową metodę znakowania wodnego dla tekstu LG wytwarzanego przez LLM ugruntowaną w przypisaniu segmentu pseudolosowym. Proponujemy również wiele technik, aby jeszcze bardziej zwiększyć wytrzymałość naszego algorytmu sygnalizacji wodnej. Przeprowadzamy szeroko zakrojone eksperymenty w celu oceny naszej metody. Nasze wyniki eksperymentalne pokazują, że nasza metoda znacznie przewyższa istniejące wartości bazowe zarówno pod względem dokładności, jak i solidności w zakresie zbiorów danych porównawczych. Na przykład, przy osadzeniu wiadomości o długości 20 w 200-token wygenerowany tekst, nasza metoda osiąga szybkość dopasowania 97,6%, podczas gdy najnowocześniejsza praca Yoo i in. osiągają tylko 49,2% Dodatkowo udowadniamy, że nasz znak wodny może tolerować edycję w odległości edycji wynoszącej średnio 17 dla każdego akapitu w tym samym ustawieniu.”
Badacze z Cornell University zaprezentowali tutaj nową, skuteczną metodę znakowania wodnego tekstów, które wygenerowały modele językowe (LLM). Metoda ta dzięki osadzaniu ukrytych informacji (bit stringów) pozwala śledzić źródło treści. Ich rozwiązanie znacząco przewyższa dotychczasowe metody pod względem dokładności i odporności na edycję tekstu. Ma to kluczowe znaczenie w kontekście walki z nadużyciami, takimi jak phishing, czy dezinformacja.
Błędy modeli AI i ich konsekwencje.
Modele AI, mimo swojej zaawansowanej konstrukcji, nie są wolne od błędów. Modele AI nie zawsze celowo umieszczają wodne znaki w tekstach. Błędy modeli AI mogą prowadzić do niezamierzonych efektów w generowanych treściach. Nie wynikają one wyłącznie z błędów technicznych. Takie znaki mogą też powstawać w wyniku nieprzewidzianych interakcji między modelem, użytkownikiem i systemem publikacji. W praktyce oznacza to, że nawet tekst, który wygląda poprawnie może zawierać elementy, które model dodał przypadkowo np. niewidoczne sygnatury, zakodowane wzory czy zniekształcenia stylu. Z czasem takie błędy mogą wpłynąć na wiarygodność, SEO, a nawet na kwestie prawne.
Wodne znaki w tekstach AI mają służyć transparentności, jednak w praktyce ich obecność może prowadzić do wielu nieoczywistych komplikacji:
- Błędy treningowe – źle wytrenowane modele mogą automatycznie dodawać ukryte znaczniki do tekstów AI, nawet wtedy, kiedy nie zostały do tego zaprogramowane. Takie błędy mogą prowadzić do nieprawidłowej indeksacji w Google, błędów w narzędziach do analizy treści, fałszywych sygnałów w systemach antyplagiatowych. Ale nie zawsze błędy w kodzie wpływają na pozycjonowanie, czy SEO.
- Półautomatyczne „mutacje” treści – niektóre platformy CMS, albo zewnętrzne integracje mogą modyfikować tekst w trakcie kopiowania, albo publikacji np. przez nieświadome wprowadzenie niewidzialnych znaków. W efekcie tekst wygląda poprawnie, ale zawiera cyfrowe „zanieczyszczenia”, które mogą wpłynąć na SEO i legalność treści.
- Konsekwencje prawne – osoby korzystające z AI mogą świadomie, albo i nie, wprowadzać do treści wodny ślad AI, które później mogą posłużyć jako dowód naruszenia licencji. Właściciele technologii mają prawo dochodzić roszczeń, szczególnie gdy ktoś publikuje treści wygenerowane przez AI bez odpowiednich uprawnień. Taki znak może ujawniać kto wygenerował tekst, jakim modelem, a nawet w jakim czasie.
Uważam, że warto wiedzieć także o tym, że niedopasowany prompt = nietypowa sygnatura. Źle sformułowana komenda (prompt) także może spowodować, że AI wygeneruje treść z charakterystycznymi błędami. Te błędy będą się powtarzać w kolejnych tekstach, tworząc unikalny „profil” użytkownika. W rezultacie, zamiast unikalnego tekstu, będziemy publikować wariację powtarzalnych schematów, które łatwo będzie można przypisać do konkretnego narzędzia, albo konta.
W świecie, w którym odbiorcy i systemy mogą śledzić, analizować i kwestionować każdą treść, odciski cyfrowe w tekstach AI zyskują nowe znaczenie, które wykraczają poza technologiczną ciekawostkę. To narzędzia, które służą do weryfikacji, dowodu w procesach sądowych, ale i są symbolem cyfrowej odpowiedzialności. Dzisiaj nie wystarczy już tylko stworzyć „ładny tekst”. Warto wziąć odpowiedzialność za publikowane treści, zarówno pod względem ich legalności, jak i możliwych konsekwencji. Do kogo tekst wcześniej należał i jakie niesie ze sobą ryzyka jego publikacja.
Kluczem do bezpiecznego budowania marki, bloga, czy komunikacji eksperckiej jest zrozumienie tego, jak działają znaki wodne w tekstach AI. Jak je wykrywać i jakie błędy mogą wynikać z ich ignorowania. Bez względu na to, czy pracujemy w marketingu i edukacji, mediach, czy e-commerce, warto przestać traktować AI jako źródło darmowego tekstu. Generator treści to narzędzie, które ma za zadnie wspierać nas, ale nie zwalniać z odpowiedzialności.
Świadoma publikacja treści z AI wymaga uważności i znajomości licencji, edycji tekstów oraz umiejętności zadawania niewygodnych, ale jakże ważnych pytań. To nie jest tylko moda, to nowy alfabet twórczości.
Jeżeli chcemy naprawdę tworzyć, a nie tylko kopiować, zaufajmy sobie, swojej wiedzy, a nie tylko algorytmom. AI powinno być wsparciem, ale nie tylko substytutem.
Kończąc dla wytrwałych, którzy doczytali do końca zostawię wisienkę … Jeżeli chcemy tworzyć teksty, które będą wartościowe dla czytelników oraz będą się wbijały w algorytmy Google i programów AI, to warto postawić na poszerzenie wiedzy. Tematy na które warto zwrócić uwagę to np. heurystyki, halucynacji programów AI oraz elementów predykcyjnych, które coraz mocniej wpływają na SEO.
Q&A
Czy każdy tekst AI zawiera znaki wodne?
Wszystkie modele AI, które generują treści wstawiają do nich swoje specyficzne znaczniki na różne sposoby. Jednak nie wszystkie zostawiają je tylko w kodzie HTML. Warto założyć, że nie zawsze będziemy wiedzieć, jakie ślady AI są dodawane do tekstów przez program AI. Brak informacji w regulaminie nie oznacza braku znaków.
Czy redagowanie tekstu usuwa wodne ślady z tekstów AI?
Redagowanie tekstu nie zawsze usuwa wodne ślady z tekstów AI. Głębokie przekształcenie struktury zdań może „rozbić” algorytmiczny wzorzec. Jednak znaki ukryte w kodzie (np. ZWS) trzeba usunąć ręcznie, albo za pomocą odpowiednich narzędzi. Warto już dzisiaj założyć, że jeżeli chcemy unikać ukrytych śladów zostawianych w treści przez programy AI, to powinniśmy tekst napisać sami.
Czy znaki wodne w tekstach AI są legalne?
Ślady cyfrowe zostawiane w tekstach są legalne o ile są stosowane w celu weryfikacji, albo ochrony treści. Problem pojawia się wtedy, kiedy użytkownik nie ma świadomości ich istnienia, a mimo to ponosi prawne konsekwencje. Dlatego niebawem zapewne zmienią się przepisy prawa zawiązane z generowanymi treściami. Wtedy zmienią się także regulaminy i licencje programów AI.
Czy AI może wykryć tekst AI?
AI może wykryć tekst wygenerowany przez program AI, ale z ograniczoną skutecznością. Narzędzia działają na zasadzie statystycznej analizy stylu. Im bardziej redagujemy treść, tym trudniej jest wykryć tekst AI. Na dzień dzisiejszy nie spotkałam się z programem, który posiadałby aktualny algorytm, który pozwoliłby mu na skuteczne wykrycie tekstu wygenerowanego przez sztuczną inteligencję. Programy, które generują treści rozwijają swoje algorytmy, dlatego też programy, które je wykrywają, także powinny uaktualniać swoje algorytmy.
Czy mogę opublikować bez obaw tekst wygenerowany przez AI?
Można opublikować bez obaw tekst wygenerowany przez program AI, zwłaszcza wtedy kiedy znamy warunki regulaminu i licencji programu. Niektóre firmy zastrzegają sobie prawa do wygenerowanej treści. Dodatkowo warto wykonać własną redakcję, sprawdzić tekst pod kątem ukrytych znaków i nie publikować skopiowanego tekstu 1:1. Sporo programów AI podczas generowania tekstu zostawia linki do stron z których pochodzi dana treść. Dlatego warto już dzisiaj zadbać o wykazanie źródła.
Czy znaki wodne w tekstach AI mogą być dowodem w sądzie?
Ukryty cyfrowy odcisk może służyć jako dowód naruszenia praw autorskich, licencji, szczególnie w przypadku nieautoryzowanego wykorzystania tekstu w celach komercyjnych.
Czy wodne ślady AI wpływają na SEO?
Wodne ślady AI umieszczone w tekstach mogą wpływać na SEO zaburzając analizę treści przez algorytmy wyszukiwarek. Mogą także powodować błędne indeksowanie, albo obniżenie pozycji strony w wynikach Google.
Źródła:
Kirchenbauer, J., Geiping, J., Goldblum, M., Carlini, N., & Goldstein, T. (2023). A Watermark for Large Language Models. arXiv preprint arXiv:2301.10226
Wiedza zawarta w tym artykule opiera się na doświadczeniu, własnych analizach, obserwacjach oraz dostępnych źródłach.
Tekst napisany z lekką pomocą ChatGPT
Zdjęcie pochodzi ze stock Pixabay






Świetny artykuł poruszający ważny temat znakowania wodnego w tekstach generowanych przez AI. Warto również wspomnieć o nowoczesnych technikach, takich jak SynthID od Google DeepMind, które umożliwiają niewidoczne znakowanie tekstu bez wpływu na jego jakość. Dodatkowo, zaawansowane metody, takie jak Unigram-Watermark, wykazują odporność na manipulacje, co zwiększa ich skuteczność. Jednakże, należy pamiętać o potencjalnych problemach związanych z detekcją treści AI, takich jak fałszywe oskarżenia o plagiat, co podkreśla potrzebę ostrożnego stosowania tych narzędzi.